I tried some Chinese news sites, and more than one paragraph was translated to English perfectly. Very impressive. But my Chinese wife asked me to put in some text from Weibo, China's Twitter clone, and the translations were nearly incomprehensible. She insisted that the samples we chose were not slang but were everyday colloquial Chinese that is easily understood by anyone. My guess is that Google's training set is mainly Chinese news sites, which are a formal type of Chinese that is quite different from spoken Chinese. I wonder if they can scrape Weibo messages to improve their translations.
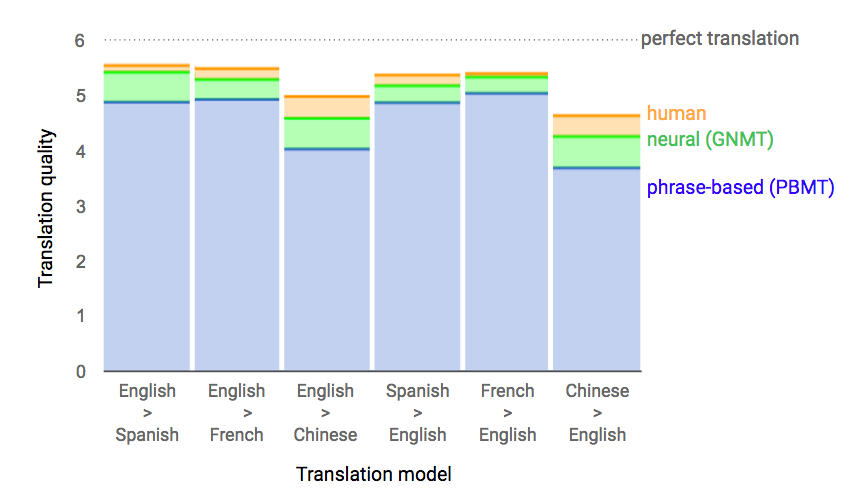
It's a pity that this graph shows only 3 languages (except for English), I would love to see such graph for all the languages available in google translate.
I tried with some facebook comments and articles posted to facebook in chinese and the results were pretty much incomprehensible as well. It was so bad, it makes me wonder - has google actually enabled this for all users?
Their training dataset is almost certainly biased towards 'formal' Chinese sources, e.g. newspapers, news broadcasts, and so on. This is probably true for every language translation dataset, but at least anecdotally I can confirm the massive disconnect between spoken and written Chinese.
It's really interesting culturally, since modern written Chinese is split between Simplified (PRC) and Traditional (HK/TW/etc), because Mao thought Traditional was too difficult for the proletariat. Yet official national news sources in China are almost always given in formal Chinese, which nobody outside of the elite really speaks!
This effect is also extremely noticeable in the Finnish language. The rules of Finnish grammar are followed much more strictly when writing any kind of text, than they are when speaking. There are rules of grammar that are always followed when writing, but are not really that important when speaking.
As an example, take the sentence "kirja on työpöydälläni", which means "the book is on my desk". The word "työpöytä" (desk) gets two suffixes, "-llä" which corresponds to the preposition "on", and "-ni" which is the first-person genitive. But when speaking, this would easily come out as "kirja on minun työpöydällä" instead, where the noun doesn't isn't in the genitive form at all anymore, the genitive has become a separate word which is a pronoun with a genitive ("minun").
If you study just the grammatical rules and nothing else, you might think that the second sentence is obviously grammatically wrong. (Because according to the rule, the noun must change its case to correspond to the genitive.) Yet it's completely acceptable to say it aloud that way, even in a formal context, and nobody would bat an eye. While at the same time if you put it this way in any kind of writing, you would almost surely be notified by the grammar police that you have made a grave mistake.
I find this duality of language fascinating. And this will certainly continue producing problems for the field of machine translation. Google Translate is infamous in Finland for being near-useless for translating anything to or from Finnish.
The GP was about Weibo messages/posts, and how those written messages reflect colloquial or spoken language much more closely than something from Sina.
Written text in SMS and twitter tends to a lot closer to the way people speak, whereas newspapers are a lot more "polished". So there is definitely a bias depending on what you train your algorithm on. Also, topics and vocabulary may differ widely so if you train on newspaper, your algorithm will struggle with phone conversations.
If you are talking about Modern Spoken Mandarin (or written Spoken Mandarin: SMS, social media) vs Modern Written Mandarin I don't think the gap is that large compared to other languages. Certainly a lot less than the gap between written Colloquial English and Formal English (more words of Latin origins).
Looking at the People's Daily website (which is presumably an official news source in China), it looks like standard newspaper Chinese. Should be readable for most Chinese people with at least primary education.
"I don't think the gap is that large compared to other languages"
As someone learning Chinese, I can sympathize with Google Translate. Spoken Mandarin doesn't give you nearly as much context as more modern written Mandarin. I have no problem reading a newspaper but real conversation between Chinese people is just lost on me. It's not just a pace of listening thing, there is just too much of the sentence that isn't said out loud.
i tried the same with portuguese comments/text where i always felt Facebooks translation was pretty bad and in google translate it is a lot better, to the point you hardly notice it's translated by an algorithm at all.
Actually I still think Google is pretty bad at going between all Portuguese variants.
It puts them all in the same bag, resulting in very strange translations when using it as target language.
Going the other way around, I am yet to properly translate any of the variants into a way that all verbs and articles keep their sense across languages.
For example, translating você to either Du or Sie in German, depending on the Portuguese variant being used.
I tried with some random article from dwnews and it worked very well. Just about the only problems I saw was in verb tenses. For example, in one place the translation used the word "exit", where it seemed to me it would have been better with "have exited" or at least "exited".
This is understandable given the endpoints. Chinese almost completely lacks verb tenses, expecting everything to come from context. But AIUI, English is pretty much the opposite extreme, having more explicit verb tenses than most other languages. So the translation isn't able to fully flesh out from context what the English tense should be, and just gives a reasonable compromise.
I can confirm: I took some of the most difficult text I could find (some articles from lesswrong.com) and translated them from English to German with Google... the German translation is very close to perfect now- Comparable to any manual translation I could do on my own, being fluent in both languages.
I tested a douzen sentences (English to German with texts from lesswrong.com) and it is very good, but not very close to perfect; I could spot a minor error in nearly every sentence.
EN: As we wrap up the 2016 survey, I'd like to start by thanking everybody...
DE: Als wir die Umfrage 2016 abschließen, möchte ich zunächst allen danken...
EN: This seems consistent with the hypothesis that the LW community hasn't declined in population so much as migrated into different communities.
DE: Dies scheint im Einklang mit der Hypothese, dass die LW-Gemeinde nicht in der Bevölkerung sank so viel wie in verschiedene Gemeinden abgewandert.
"In the medieval time of a roman emperor who had no regard for life and engaged in the most atrocious habits of mass slaughter, babarian footsteps made it all the way to the capitol."
In der mittelalterlichen Zeit eines römischen Kaisers, der keine Rücksicht auf das Leben hatte und sich mit den grauenhaftesten Gewohnheiten der Massenschlachtung beschäftigte, machten babarische Schritte den ganzen Weg bis zum Kapitol.
"Zum Abschluss der Umfrage 2016 möchte ich zunächst Ihnen allen danken". Note the "Ihnen", which isn't there in English but required for an idiomatic translation.
"Dies scheint im Einklang mit der Hypothese, dass die LW-Gemeinde nicht in der Bevölkerung abgenommen hat, sondern eher in andere Gemeinden abgewandert ist". Note that the "not so much" qualifier is applied to the first half in English, but the second half in German ("sondern eher" → "but rather").
The first sentence is probably better started with "Zum Abschluss" than "Als wir abschliessen".
The second sentence is not wrong per se, I am having trouble coming up with a better translation. I'd probably use Communities instead of Gemeinden, as Gemeinde is more municipality or parrish, and the original sentence refers to online communities, which for me are not entailed in Gemeinde(in this context at least).
"Als" is not correct here. It should be "Da wir die Umfrage 2016 abschließen ..."
In the second example it should be "... dass die LW-Gemeinde in der Bevölkerung nicht sank sondern eher in verschiedene Gemeinden abgewandert ist."
But I'm having a hard time translating "so much as" in this context to German.
I don't think I agree with 'very close to perfect'. Just entering a random sentence I got the following:
Humans are far better than other species at altering our environment to suit our preferences.
Die Menschen sind weit besser als andere Arten bei der Veränderung unserer Umgebung, um unsere Vorlieben.
The German is pretty much wrong and the actual meaning of the original sentence is hard to deduce in my opinion. That being said, computer translation has come very far in the last decade.
I'm not sure if the Portuguese->English translation just isn't as good as English->German, but it's certainly nowhere close to a fluent manual translation.
In fact, the main difference seems to be less tripping up on mostly inconsequential small pieces of English grammar. It seems to have the same trouble as the old version in translating the meaning of sentences.
Wow I looked at this between Korean and English -- it's very impressive. Amazing, in fact, b/c Korean and Japanese seem to be the hardest to get right(?). There were inaccuracies but in the past even getting the gist of something was difficult. I then tried translating newspaper text from Korean to French, but that was making far more mistakes... Also, going from English to Korean is better but, for example, "I'll go nuts" turns into "I'll bear fruit" (나는 열매 맺을거야) and so on. And of course the social / honorific stuff can't be conveyed yet. But it's head and shoulders over the previous versions. Amazing. A bit frightening.
Just reading Korean is really hard for me b/c I'm not Korean... so this should help. It might not help my Korean language skill, though... or will it? Of course it also tends to devalue my skill of reading in Korean... or does it?
I put in a few sentences, and it seems much better. It seemed to have trouble rearranging words and phrases over long distances (due to grammatical differences) before.
So one thing I wonder about is how well "smoothness" of the translated text reflects accuracy of the translation.
What I mean is, we already know several really impressive examples of how language models from recurrent neural networks can generate eerily natural random texts (e.g. this blogpost http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
So even if we just trained it on an English corpus and fed random numbers into it, it would still output smooth and natural-sounding English sentences. Of course, here it is actually translating, but I wonder how often it will be "overconfident", i.e. generate a plausible-sounding sentence which doesn't at all correspond to the input text. Unlike a human translator, it won't say "sorry I'm not sure what that means".
"Google e Facebook declararam guerra aos sites de Internet que difundem notícias falsas, que o buscador e a rede social vão impedir que se beneficiem de seus serviços de publicidade."
"Google and Facebook have declared war on Internet sites that broadcast fake news that the search engine and social network will prevent them from benefiting from their advertising services."
_____
After the comma (which Google misses in its English translation), the word "que" (that) should be translated as "which" in this case. Also, the reflexive "beneficiar-se" (to benefit onself, used here in the imperative/command tense) seems to have confused Google, likely due to having missed the comma earlier. I took out the middle part of the second clause and translated only "que vão impedir que se beneficiem" and Google got it right, translating it as "which will prevent them from benefiting".
I have experience translating from BR-PT to EN (and even vice-versa for my own testing), and BR-PT native speakers have a habit of writing long-winded, run-on sentences in all sorts of published literature. I'm curious to see Google understand that aspect, which even trips me up once in a blue moon.
Before this update it was translating "Eu tenho 30 anos" as "I have 30 years" which was literal but didn't make sense in the most common context of that phrase. I'm pleased to see that it now correctly translates it as "I'm 30 years old".
I'm a Portuguese native speaker. I saw a clear improvement, but I noticed errors to identify who is the subject of the context. Unlike English which the subject always is explicit (repeating a lot the pronouns I, you, they, e etc) in Portuguese we normally omit. Is quite challenging for a machine understand that.
I'm a native English speaker. Once in a blue moon, although meaning "very rarely", is fine since I'm using it to say "every so often". But, yes, if we want to nitpick, "which even trips me up very rarely" doesn't sound great. Although, "which even trips me up every so often" does work.
I couldn't figure out at first why it felt off to me as well, but I think you hit the nail on the head. It's not wrong, it's just a little off/unusual.
> I figure someone at Google thought it was funny to say that blue moons occur approximately every ... 992 days.
Not sure if your comment's implying it's a random number picked for amusement? That figure (2.7 years) seems about right to me -- the frequency of a blue moon is necessarily the same as the frequency that a lunisolar calendar has to add a leap month, which is every 2 or 3 years. I don't see any reason to doubt Google's number.
Find it really interesting that Google Cloud Platform customers get access to this immediately.
Bodes well for Google cloud, putting out your latest and greatest eases my thoughts as to whether its a first class citizen within Google. (I know the head of the Cloud unit is on Google's board which was a major sign of taking 'cloud' seriously.)
Japanese translation has improved recently but it still often generates pretty silly results. Though this language is one big Winograd schema so it would be hard to improve without strong AI. Shameless plug for my own Japanese translation service http://ichi.moe which doesn't even attempt to build a sentence and relies on the user to solve ambiguity.
Speaking of Winograd Schema, it seems to manage some pretty simple cases, which I thought was pretty cool. No idea if it could already do that before this update, though.
It correctly translated "I asked my son to take my bag because it was very heavy" and "I asked my son to take my bag because he was very strong" correctly from French, despite the 'he/it' both being the ambiguous 'il' in French.
Since they listed Japanese in the list of languages, I went ahead and took the first news on yahoo japan, which was translated to:
"Government and ruling parties will raise the upper limit of the annual income (under 1,300,000 yen) of spouses subject to deduction to 1.3 million yen or 1.5 million yen, over the review of spousal deduction, which is the focus of the tax reform debate focused on in the 2017 tax reform debate I entered the adjustment with the plan. If the annual income of each husband exceeds 13.2 million yen (11 million yen for "income" minus the amount deemed necessary expenses for work), 11.2 million yen (9 million yen same), it is excluded from the system. The ruling party taxation study committee will review these two plans and aim to include it in the tax reform outline of FY2005"
Seems like there's still a long way to go.
(Copy/pasted original text:
2017年度の税制改正議論で焦点となっている配偶者控除の見直しを巡り、政府・与党は、控除対象となる配偶者の年収上限(103万円以下)を130万円か150万円まで引き上げる案で調整に入った。それぞれ夫の年収が1320万円(仕事の必要経費とみなされる額を差し引いた「所得」では1100万円)、1120万円(同900万円)を超える場合は制度の対象外とする。与党税制調査会はこの2案を軸に検討し、17年度税制改正大綱に盛り込むことを目指す)
I wonder how it went from 103万円以下 to "under 1,300,000 yen"
Actually the English translation seems to produce surprisingly well formed sentences. I'm not a native English speaker, and these kinds of long winded sentences with numbers in them are always confusing, but at least I don't see any _obviously_ malformed phrase.
I actually think this update is now worse for at least Japanese -> English. The sentences it produces are now often much more readable, and much more wrong. Without some background in the language there is no way for the user to tell; previously where it lacked a match it would produce a translation that made it obvious it wasn't able to grok the meaning, now it seems to 'fill in the blanks' in a way that makes the sentence readable in English regardless. I guess this is much like a non-skilled human translator, but given the assumption that Google knows all this gives a false impression of the accuracy. It would be really helpful I think if Google Translate would provide some kind of confidence level on its accuracy for a translation - a bar graph, stars, something...
Phone typing has created a similar problem just within English. Typos are easy to interpret, and virtually never affect the meaning of a phrase. Random word substitutions are much harder, and are quite likely to make the phrase in which they appear into complete nonsense.
The system has lost track of the subject (the government and ruling party) and put in "I" as the most likely candidate. This error is pretty dumb, to be honest, and no halfway competent human would make this mistake.
>What's the part of the sentence that follows it supposed to mean?
"entered the adjustment with the plan" is for ~案で調整に入る, which is quite difficult political lingo. The sentence should begin "the government and ruling party have entered discussions regarding (two different) proposals to raise the ..."
>each husband?
"Each" should be "[under] each plan"; the original omits the subject. Figuring out the meaning of それぞれ here would be hard for a lot of quite advanced Japanese learners, I think.
>funny, it translated 17年度 as meaning 平成17年
Actually this is the more common interpretation - if it didn't say 2017 earlier in the text this would be a pretty safe bet. I guess they don't do text-level analysis yet?
---
Anyway, I agree with what everyone else is saying - this is an impressive leap in making intelligible output for JtoE, but as a translator I'm not fearing for my job just yet.
それぞれ夫 is literally each husband. While the introductory sentence uses the gender neutral 配偶者 (Spouse), this sentence actually does appear to make the assumption that husbands are the ones claiming the deduction and not wives (which is probably true in 90% of cases).
When taken out of context, that would be true. That's however not the case in the original full text. See getoj's sibling reply. It would be clearer if there were a comma between それぞれ and 夫, though, but I don't know if that's my French bias wanting punctuation or if that would be "idiomatic".
I've tried translating some paragraphs from English to Japanese and back and it now seems intelligible enough to be useful. Previously, it produced complete gibberish.
The mistake you pointed out seems rather odd. Computers are supposed to be good at arithmetic. With my limited knowledge of Chinese (that part is all Kanji) even I would get that right (under 1,030,000JPY). But that's the problem with neural or statistical translation - even with the code available, you can't easily tell why it's happened.
Perhaps it got confused because 130万円 appears later in that sentence.
It translated okay for me, perhaps you meant 130万?
> I wonder how it went from 103万円以下 to "under 1,300,000 yen"
There is no million in Japanese counting, but 1万(man) is 10000. I think google did this to make reading easier, as otherwise you would have to make this conversion in your head when reading.
It's still a ways from becoming self aware. Here's a piece of an old family letter in German:
Meine lieben Kinder!
Sveben brachte Frl. Moldelen die Rarte
von Herrn Thomass mit du schoene Nachricht,
dass R. doch endlich gut in Br. ankam. Was
bin ich froh daruber! Und nun hoffe ich doch
schr, dess Roesi Samstag mittag in R. ankem,
sich schrubben u aus schlafen konnte. Dickes,
hast Du Dir nichts gehalt bei der Rums Scheru?
Mittwoch ging ich nach Tisch zur Stadt, be-
sorgte Einiges u wollte im Hansahed in der
Wilm. Str. haden. Musste aber 2 1/2 St. werde,
dann war es aber sehr schoen. Ich mechte
dann das Abendessen u erst um 8 h ging
ich rauf ins Zimmer zum Tisch decken de
fand ich den Zettel von Frl. B. mit Frl. Mol.
dehns grusse von Dir! Meinen Schrucke koemmt
Ihr Euch denken.
My dear children!
Sveben brought Ms. Moldelen the Rarte
From Mr. Thomass, with a nice news,
That R. finally got well in Br. What
I'm glad about it And now I hope
Schr, dess Roesi Saturday noon in R. ankem,
Could scrub u from sleeping. Thick,
You have nothing to do with the Rums Scheru?
Wednesday, I went to the city,
Caused some u wanted in the Hansahed in the
Wilm. Str. Had to be 2 1/2 St.,
Then it was very beautiful. I want to
Then the dinner u went around 8 h
I rise up into the room to cover the table
I found the note of Miss B. with Miss Mol.
Dehns greetings from you! My shrine
You think.
Hi, native German speaker here. Quite a few things in your letter do not make any sense whatsoever, I suspect that is due to the transcription from the handwriting. I don't think dialects have much to do with it. E.g. I don't think "ankem" is dialect, I think that is just a transcription error. "a" and "e" can look very similar in handwriting.
German hasn't changed that much since the 1940s, however, there are dialects from the East (Prussia, Pomerania, Silesia) that are dead today. But as far as I know, they were not that different from today's High German.
Here is what I can guess from your original text. I'll expand the abbreviations I understand and correct the spelling. The translation is rather free, I'm trying to catch the sentiment so that the text makes sense to you.
---
Meine lieben Kinder! Sveben (?, if that's a name I have never heard it) brachte Fräulein Moldelen die Karte von Herrn Thomas mit der schönen Nachricht, dass R. doch endlich gut in Br. ankam. Was bin ich froh darüber! Und nun hoffe ich doch sehr, dass Rosi Samstag Mittag in R. ankam, sich schrubben und ausschlafen konnte. Dickes, hast Du Dir nichts geholt bei der ... (no idea here)? Mittwoch ging ich nach Tisch zur Stadt, besorgte einiges und wollte im Hansabad in der Wilhelmstraße baden. Musste aber 2 1/2 Stunden warten, dann war es aber sehr schön. Ich machte dann das Abendessen und erst um 8 Uhr ging ich rauf ins Zimmer zum Tisch decken, da find ich den Zettel von Fräulein B. mit Fräulein Moldelens Grüßen von Dir! Meinen Schrecken könnt ihr euch denken.
My dear children! Sveben brought Ms. Moldelen the postcard from Mr. Thomas with the happy news that R. has arrived well in Br. after all. Imagine my relief! And now I'm hoping very much that Rosi has arrived Saturday noon in R., and that she was able to clean herself and have a good sleep. Sweety, didn't you get anything from ...? Wednesday I went into town after the meal, made some errands and wanted to take a swim in the Hansabad at Wilhelmstraße. Had to wait for 2.5 hours, but then I had a great time. I then made dinner, and only at 8 o'clock I went upstairs in the room to set the table, that was when I found the note from Miss B. with Ms. Moldelen's greetings from you. You can imagine my shock!
---
Admittedly the last sentence does not make too much sense. Perhaps I guessed wrong from your transcription, hard to say.
Well but that letter has several errors ("mit du schoene Nachricht", "schr" instead of "sehr", "ankem" is ancient spelling for "ankam", "be- sorgte" was a hyphenated line break...) and uses weird abbreviations that require context (R. is a person, Br. is a place). No wonder it's having trouble.
Thank you for the corrections. I haven't been able to talk any native German speakers into helping fix the errors.
In general, though, I've found Google Translate to fall over and produce gibberish with a single misspelling or grammatical error. That's ok when translating professionally edited text, but language in common usage tends to be a lot messier.
Here's a fixed transcription, with bits I'm unsure about in italics:
Meine lieben Kinder! Soeben brachte Frl. Moldelen¹ die Karte von Herrn Thomas mit der schönen Nachricht, dass R. doch endlich gut in Br. ankam. Was bin ich froh darüber! Und nun hoffe ich doch sehr, dass Rosi Samstag mittag in R. ankam, sich schrubben und ausschlafen konnte. Dickes, hast Du Dir nichts geholt bei der Rums Scheru? Mittwoch ging ich nach Tisch² zur Stadt, besorgte Einiges und wollte im Hansabad in der Wilm. Str. baden. Musste aber 2 1/2 Stunden werde, dann war es aber sehr schoen. Ich machte dann das Abendessen und erst um 8 Uhr ging ich rauf ins Zimmer zum Tisch decken, da fand ich den Zettel von Frl. B. mit Frl. Moldelens¹ Grüßen von Dir! Meinen Schrecken³ könnnt Ihr Euch denken.
¹ that's probably supposed to be the same name twice
² "nach Tisch" (after table) is old for "nach dem Essen" (after lunch/dinner)
³ old for "Meine Überraschung" (my surprise)
I have no idea what "Rums Scheru" could mean. Maybe it's referring to some event, hoping that the person didn't catch an illness there.
A lightly edited translation (not perfect, I just fixed some Google Translate mistakes) would be something like:
My dear children! Miss Moldelen had just brought Mr. Thomas's card with the good news that R. had finally arrived at Br. How glad I am about that! And now I hope very much that Rosi arrived in R. on Saturday afternoon and got a chance to scrub and sleep. Thick (referring to a person who's a bit thick, as a nickname), I hope you didn't catch anything at the Rums Scheru? On Wednesday I went to the city after lunch to run some errands, and wanted to go bathing in Hansabad in Wilm. street. Had to wait for 2 1/2 hours, but then it was very nice. I then went to make dinner, and at eight o'clock I went upstairs to set the table, where I found the note from Miss B. with Miss Moldelen's greetings from you! You can imagine my surprise.
Thank you, you guys are awesome! The letters are a bit of a treasure, as they describe my grandmother's experiences as a housewife before, during, and after the fall of Berlin. Many abbreviations are place names, such as R is for Rohrbach, or names I presume are neighbors.
The thought has crossed my mind, since everyone from then is long dead now. It reminds me of the cache of Civil War letters recently discovered and discussed here.
I have a lot of other things I recognize have some historical value, like my father's WW2 diary, and some amazing color pictures he took during the Korean War. (Any other pictures of the KW I've seen are grainy black & white, but my dad's pictures are in crisp, full color.)
I'm not sure if it's a moral obligation, but you certainly do have some kind of imperative to share those precious records with the world. A simple gallery site that let people contact you for reproduction rights? A publisher? Submission to Archive.org... Keep us posted if you do?
> In general, though, I've found Google Translate to fall over and produce gibberish with a single misspelling or grammatical error.
I wonder if one could couple auto-correct and translation in a way where the error rates don't multiply. I.e. only attempt corrections where the translation says it has low confidence.
P.S. The German text is transcribed from a handwritten letter. I don't know German very well at all, which makes my transcription a bit suspect. I've found it is very difficult to transcribe cursive in a language that you aren't fluent in.
It'd be nice if someone was working on a system to transcribe cursive, in all its sloppy, messy glory.
Yeah, conversational German has changed quite a bit. It's less formal nowadays, and many expressions have changed. The GP isn't referring to a regional dialect, though - more like an older revision, in software terms ;)
German has not changed a lot since then, but perhaps more than English. I mistook some of the garbled words for some local/old dialect. The transcription is just really bad, but the original also seems to contain a lot of abbreviations.
1. it's in a mix of cursive Suetterlin script and more modern forms. Many letters can only be distinguished if you know the context.
2. my German is limited to a few hundred words.
3. she didn't write very clearly, the last two letters of a word tended to be just a line :-)
But I can get far enough to get the general sense of what the letters were saying. The translations posted here, however, show how limited machine translation still is, and hence how far we still are from the singularity.
I am not sure this tells us that the singularity is very far away. It just tells us that this particular system is still not universal. I mean, perhaps there are really only a couple of components missing to make it a general AI system (e.g. an associative working memory, ability to attend to parts of the text multiple times). It is hard to quantify how difficult it would be to invent these components. It could be 5 years or 50.
My German colleagues assure me Google's neural network needs a bit more training on that one. I often use Google Translate to go back from the German I have (badly) created to English, as a further check that it's somewhat understandable. In terms of it replacing asking real humans for help... I think it's still a long way away, but good to see Google investing in it.
It clearly failed on context there - "fällig" does mean "due", but when referring to an invoice. "due" isn't used for baby delivery dates in German, the sentence would be structured differently, probably something like "Unser Baby kommt im Januar" (literally "our baby is coming in January"). That's exactly the kind of thing I hoped this new model would catch, but apparently that's still a bit too much to expect.
This one is actually not too bad - there is only a very slight difference between "due" (which can mean both something like "shall be done" and "bound to happen") and "fällig" (which means only "shall be done"). Grammatically and semantically, this almost never matters, it only misses the much higher cultural context of it being slightly weird to refer to a baby as a "task".
At least it's clearly understandable and grammatically correct, and only a slightly odd (distant) phrasing. I wouldn't be surprised at all if I heard someone saying it exactly like that in an off-the-cuff remark.
Interestingly I wouldn't know how to translate the German back to English while preserving the feel of the phrasing. Languages just don't map 1:1.
This might create a new problem: Without obvious mistakes like word salad, you can no longer evaluate the probable quality of a translation. You might read a translated news article and be oblivious to missing or mistranslated facts, because the text flows well and sounds convincing. The old method had telltale signs of breakdown and the resulting text was always clumsy enough to warn anyone off with regards to trusting it too much. Hmmm. Interesting times.
If they manage to reach 99% translation accuracy of German texts, I say they achieved a very remarkable feat.
I know that Modern Standard Arabic is not supported yet with the NML system but I just went and tried the translation for a small excerpt from an article on DW [1]
"بالرغم من عدم وجود تأكيدات رسمية منها على نيتها للترشح مجددا، قال قيادي بارز في حزبها إن المستشارة ميركل ستترشح لولاية رابعة. جاء ذلك على لسان المسؤول عن لجنة العلاقات الخارجية في البرلمان الألماني نوربرت روتغن. "
"Despite the lack of official confirmation, including the intention to run again, a senior leader of her party said that Chancellor Merkel will stand for a fourth term. This came on the tongue in charge of the Foreign Relations Committee in the German Parliament Norbert Rongn."
Of course, the translation is not perfect but good enough. However, I believe that they could do better by working on their Arabic text-to-speech synthesizer and having a toggle option for diacritics that would definitely help them with the synthesizer as there are many words pronounced wrong or actually very wrong that's disappointing.
All in all, great work by the people at Google Translate.
At first I was offended but then I realized he was just pulling my leg. He smiled and said, "I'm just yanking your chain." She added, "Don't mind him, he's always rattling someone's cage."
Zuerst war ich beleidigt, aber dann merkte ich, dass er gerade mein Bein zog. Er lächelte und sagte: "Ich zerrle gerade deine Kette." Sie fügte hinzu: "Kümmern Sie sich nicht um ihn, er ist immer rasseln jemandes Käfig."
The translation industry is $40bn/pa and growing at some 13% pa. Demand for human translation might well rise alongside these innovations as awareness of the benefits and ROI of good translation spreads.
Probably the trend of using translators to edit machine translations will accelerate, but I can't see that as really of benefit to the individual translator.
Definitely post-editing will continue. I was mainly talking about the market itself growing, with the assumption that a large portion of that market will demand high-quality, human translation of marketing copy, instructions and legal texts.
German to English works amazingly well... I was able to fool it the other way round though. Here some crazy German sentences and the English version:
"Das altbacken emotionale Muster einer zerstoerten Ehe aehnelt dem Neutrino-sturm eines sterbenden Gasgiganten"
-"The old-fashioned emotional pattern of a ruined marriage resembles the neutrino storm of a dying gas giant"
(In the above I tried to confuse it using archaic words mixed with completely disconnected topics in the same sentence while still being grammatically correct.)
"Das verrueckte an der Sache ist der enorme Unterschied zwischen digitalem Denkmuster und analogem Sachverstand" -
"The crazy thing about this is the enormous difference between digital thought patterns and analogous expertise"
When I read something about google translate (related to Latvian or not), there is a certain phrase I love testing - "Hard rock fan".
There were times when it was translated literally - "a fan, manufactured from solid rock" (cieto iežu ventilators). Then for a brief moment it was translated as originally intended. Now, however, it translates to nonsense ("hard rock ventilators"), which losely may be translated back to English as "Hard rock fan", where "fan" refers to that thing which moves air around.
However, an article from Latvian news site was translated to English unexpectedly good. Which was not the case for English to Latvian translation, sadly. But it makes some kind of point if we consider English as lingua franca.
In one sense, calculators and computers haven't made learning arithmetic and other math less important. On the contrary.
Maybe in a similar way, by increasing the amount of communication between speakers and writers of different languages, tools like this might actually make language learning _more_ important? Or is that an interesting thought but completely wrong? Perhaps speaking and listening will gain in importance while writing and reading will decrease? Or is it not worth the time and trouble to learn another language anymore?
A penny for your thoughts. (OK, not a real penny ;)
To compare it to music it seems to me that human translating will become less used in work contexts. For example historically you either had to be rich enough to hire a musician (or a whole group) if you wanted to hear music. You could also just learn to play yourself. When the gramophone was invented I'm sure those professional musicians for parties didn't have much to do. On the other hand it's still considered positive (even attractive) to be able to play your own music when a computer could create something as well. I've actually wondered before why people learn to play music when they have famous and better music to listen to on their own phone, but there's something there that people like.
When you travel in a foreign country there is a lot of respect given for people who can speak the language that you just don't get from walking around with a human or device translator. You might get a peek into it the same way a DJ mixes together other people's music, but nobody would call them a famous musician (not a great comparison, because there are famous, successful, and talented DJs). Also in terms of understanding a culture a lot of that is formed/built in the language. The phrases and structures of a language definitely have an impact on how people think.
So basically yeah, professional business translators and translator shops will probably go way down in business. They would be seen as some kind of luxury, but language learning as a hobby/to understand a culture isn't related to professional translating at all really.
One thing that worries me is that most people might rely on computers instead of learning another language, or driving, navigating, or calculating. Computers then might outsmart us because we've become less intelligent.
A more optimistic view is that machine translation might help those of us who still want to learn other languages. Though I still think grammar rules are needed when learning other languages.
I think humans are going to benefit from a kind of "reverse machine learning" in the future, where AIs will become much more skilled at teaching humans that human teachers. No need to regret the loss of calculation, driving and translation - we don't care about riding and throwing arrows either. We will learn what is relevant in the new age.
This is not the direction that AI is heading, though. It was possible with symbolic AI - expert systems were able to justify their reasoning (Mycin) or critique a user's approach (Attending - abstract at https://www.researchgate.net/publication/303587198_Teaching_...), but neural networks are quite opaque and there's no obvious big data approach which would enable them to become good at teaching.
Some people do care about riding and archery, and are right to do so. I even care about and practise foraging for food, lighting fires for cooking on, and navigating using astronomy or compass. It's important to be able to fall back on low technology in case your high technology fails.
Actually, this tech could actually be a serious setback for language learning and communications in general. It's amazing how many people have taken the time to learn English around the world, which has made business and traveling easier.
Will there still be interest and investment in learning one of the biggest languages in the world, if you can just use translate.google.com? I hope not personally, but it does make me wonder if this will put things back somewhat as we get complacent and lean on technology to translate for us.
I don't see it happening. People still have to talk to each other, don't they? I realise google translate can translate your audio input these days, but no matter how good that speech recognition comes it's still much more awkward. It's fine for getting a taxi or getting something at a shop, but unsuitable for a real conversation. It's a bit inappropriate in a business meeting, or in an intimate talk, to speak into your phone and have a synthesised voice give a machine translation of your thoughts.
I welcome advances in machine translation with open arms, but I can only see them as an augmenter, not a replacement. Time will tell.
Right, that's exactly what I wonder about. It would be a sad irony if universal translation made us _less_ cosmopolitan.
Then again, what about the calculator analogy? I'm sure that when calculators came out, some people must have thought it was the end of arithmetic studying, for example. And, I can do calculus with a machine, but more people study calculus now than ever before. Maybe languages are no different?
I'm not sure about you, but virtually nobody I know can do anything other than basic integer division anymore. The calculator DID cripple our ability to do basic arithmetic.
Ok, so maybe Socrates wasn't entirely correct, but it doesn't mean his argument holds no value. I mean, how do we measure the impacts books have had on our brains? Learning without correct guidance can become a problem too and books and the internet encourage that, it is becoming a problem in my opinion. Teachers shouldn't yet be replaced by online videos, but they are.
Our brains are shrinking and while some think it's because the brain are growing more efficient, others think it could be that we're becoming less intelligent. In the case of the latter, how do you know technology does not have a hand in this?
This study shows that using GPS technology has affected people's spatial awareness abilities [1]. I've stopped using GPS technology because of this, I no longer wanted to feeling "clumsy" and slow when traveling or hiking. There is also some talk of "The Google Effect" [2].
I'm definitely not anti-books and I'm certainly not anti-progress, but I honestly think it's naive to believe technology is always beneficial to society, always stands for progress, or that we're ready to posses certain technologies.
That's true. That probably sounded more dismissive than I intended. I think we would do well to consider the downsides of new technologies and explicitly accept or reject them instead of just hoping for the best.
Yes, nobody calculates in their head above 100 or 1000, but the domain where calculation has really made a difference is in AI and scientific modeling, a domain far away from the small calculator with 4 operations.
Maybe people are going to limit themselves to learning a few words in a foreign language and translate the rest. But in 50 years, maybe all humanity will be learning a new language designed by AGI, a language with concepts that are revolutionary and completely different from ours, that will help us talk to the AGI on its level. Who knows what will come in languages. Google is already using a kind of interlingua to connect from any language to any language.
I mean the quality of the translation is good...but not that good for deep understanding. It is good enough for informational messages, like news stuff, but for things like reading a paper/textbook, where sometimes you need to spend hours to read certain section repeatedly in order to fully understand the meaning behind, this thing is far from being good enough to be useful.
> In one sense, calculators and computers haven't made learning arithmetic and other math less important. On the contrary.
As an aside, computers aren't really leveraged in mathematics much, outside arithmetic. I've (badly) done some final year undergraduate maths, and found myself still having to jump through algebraic hoops, rather than focusing on the big picture.
I am teaching myself statistics at the moment, and once I learn an equation, I let a CAS do it for me. Again, I am trying to use tools to take care of the lower level details - it's not really useful to do hairy integrals by hand when that's not that point or the level of what you are learning. At least that's my feeling.
Well, I can't learn every language. I speak Hungarian, English, German and some Spanish, but when when I want to read some Russian forums, or a news article in Romanian etc. then without Google translate it would not be possible.
Communicating face-to-face directly is still valued in business, even though we could replace such discussions with e-mail or IM. Humans value the direct and "emotional" connection that talking facilitates. Like intonation, facial expressions, word use etc. It's not the same if they speak to me through a speech recognizer + machine translator + text-to-speech synthesizer pipeline.
I believe they're referring to a babelfish-like device of the namesake, though it would be a nice touch if they could get the copyright for such a device.
One thing about Chrome spell checking; it uses a form of stem-ending dictionary for Turkish and does not perform actual morphological analysis. So sometimes legit words will be marked as mistakes. Such as the one in your example "yuvarlamaktır"
I may sound over optimistic but I feel this is very good for people who are interested in learning new languages. It will surely help people learn many languages with relative ease and low cost. Anyone can try out various sentences from new target language (e.g. German) and at least get a near-enough meaning from google. I can try many variations in simple sentences and get a good start, without having to rely on some human help, which is very costly in terms of money and (more importantly) time. A human teacher will get bored with me asking hundreds of variations to translate for me, but not computer. This is great, at least for me.
Some people are fearing that this means now there is no need for language learning. But I see it differently, it's like how Wikipedia/Internet opened doors of knowledge to all people who are "interested" in knowledge. Now with this tool, we have a door opened to learning other language right from within our home.
The only nagging feeling is all this is google, with google becoming more-and-more evil, this is scary.
I think it may assist with languages within the same language families, but robo-translate for those not with the same language family it's still pretty far off. I still wouldn't rely on it for anymore more than a general idea of translations, as often the robo-translate misses really important contextual items or mistranslates or doesn't handle different grammatical structures well. You'll get the general gist or overall concept, but the sentences require a lot of interpretation since they're not really proper sentences in the native language, they're just intelligible. I'm not really sure it'd be a good learning resource aside from "what is this word in [language]?" or getting the written form of common phrases. You'll get something passable, and a native speaker willing to listen or read will probably understand, but it isn't proper most of the time.
Part of this seems to be whatever is used to train the systems - going between English and Russian, for example, is not very good; my colleagues are all native Russians and can tell when I robo-translate versus when I manage to cobble together my own Russian sentences with frightening accuracy. In playing around with Google Translate and Yandex Translate, the programs seem to do really well on well known Russian texts, like famous Russian literature, while churning out some real goofy sentences in both languages when using more modern or lesser known prose.
All that being said though, I am very impressed as to how well and fast the robo-translators work. My job allows me the chance to work with people from virtually every country in Europe and Asia; our official support language is English, but pretty commonly the person best suited to be discussing the technical issues our clients need support on aren't great or comfortable with English. Quite a few times though we've been able to make it work by having remote sessions and going back and forth with Google Translate (or Yandex) in the browser while we dealt with the issues. As long as we keep the sentences relatively simple, it works well enough, and it makes the clients so happy to be able to just write in their native language and be understood. The translations may not be perfect, but I do think it's really cool that we can at least get a functional conversation going with the translate tools.
So yeah, robo-translate is pretty nice - I wouldn't say it's good for learning though; right now it's more functional than educational.
You're way better off just doing some reading (and listening to podcasts/radio if you can find materials easy enough). You'll get correct input, you'll learn things that aren't translations of things you would already say in English and you'll pick up more of the culture.
For German, there are tons of extensive reading resources (AKA "graded readers") and tons of podcasts for students.
Google translate for me is good in the pre-intermediate stage of learning. You can shove in groups of words and it's a nice heuristic. But I always keep in mind that it's likely to fall apart on longer sentences - I use it to "Fill the gaps" in grammatical constructs I know. It's a great enabling technique
I got to around upper intermediate in another language last year, and found it much less useful at that point. I was able to spot bad grammar and translations myself - I was much better off picking individual words from the dictionary.
It might be a challenge for Google to find big corpora to train on because of the somewhat restricted contexts Written Cantonese has been used in (but more power to them if they can make it work!).
I translated this line from the New York Times - "The dismissals followed the abrupt firing on Friday of Gov. Chris Christie" to Tamil. It translated "firing" as துப்பாக்கி சூடு (Gunfire). Maybe it needs to infer the contextual meaning from the earlier word "dismissals"?
My German (3rd language) is rather horrid, but I thought I'd try with "Es gibt mich Schadenfreude". In return I got "It gives me pleasure". Well, yes, but.. :-)
I then moved on to translating between Norwegian and English, both primary languages of mine (well, the latter for some 16 years), and was thoroughly impressed by the results as long as I stayed away from idioms - well, some. Try something a bit Aussie like "Up sh*t creek in a barbed wire canoe", and it'd fall flat on its face. Then, however it successfully mastered "Bedre med en fugl i hånden enn ti på taket" => "A bird in the hand is worth two in the bush".
Overall, that's really quite amazing work that the team has put in.
Ah, thanks! Yes, I do. I was 50/50 between mir and mich there.. Couldn't quite remember the use cases. Really ought to refresh my skills a bit, perhaps by finding some good German C# /asp.net tech sites to peruse.
I gained most of my knowledge from reading Das Amiga-Magazin, which I subscribed to for probably a decade. I was going to flunk before I started reading it, but ended up with nearly best grades (high school). It's surprising how actually wanting to read the subject matter can change things around.
Google Translate is arguably improving substantially with this update. The state of machine translation in general has already been better than Google Translate. The problem with the bleeding-edge systems is that they are not well distributed, no thought has been given to UX/UI, and the people who created them just want to finish their thesis and get out. Also, speed - the systems that eke out another few extra percentage points on accuracy tend to hoover up the CPU cycles, crushing their business case.
I'm not a fan of translating the 'meaning' instead of the actual wording. You lose idiom, phrasing, even the poetry. Its like I won't understand what they said, so it gets dumbed down. Like talking to a child.
My pet peeve: translators that tell you 'what they meant' instead of what they said.
I friend of mine who works as a translator said that the hardest thing for him to learn was to translate a badly written sentence in the original into to an equally badly written sentens in the target language. The first couple of books he translated he kept getting into trouble for trying to improve the author's language and punctuation.
It's absolutely possible to retain idiom, phrasing and even the poetry of a text, all while retaining meaning. Particularly if the source and target languages are culturally and linguistically similar. In fact you have to, as the translation has to retain the original meaning. The tradeoff is in not losing the above.
But sometimes that's not necessary. A reference, guide or manual, for instance. A contract. A patent. Records of legal proceedings. Scientific/medical texts. Dozens/hundreds of examples where it's not necessary.
Fiction, that's another matter, but it doesn't account for anywhere near the majority of the world's $40bn annual spend on translation.
And if you like the original so much, you can always learn the language ;)
Well for instance, I was trying to find out what "itadakimasu" says (which many Japanese persons say before eating food prepared for them). Its almost impossible to get a literal translation from anybody (including Google Translate, which says Let's Eat).
A good example - that link has eight (8!) different English translations for the phrase's meaning. Surely the phrase is made up of words, and its possible to tell us how those words translate individually!
If I break it up into 'ita daki masu' then Google Translate emits "I will start with you." Again, no idea if that's even close.
I'm tempted to think, forgive me if I'm wrong, but you may be looking at language too mechanically. Not sure if I can explain what I mean in a 2 minute HN comment, but I'll try: The word for word, literal translation, for which you express your preference in the parent comment, rarely works to translate meaning, particularly when it comes to idiom.
And I'm not talking about the grammar, but cultural references that can only be similarly expressed in translation if no matching idiom exists. An alternative strategy is to just use the original (potentially with an explainer, under creative license) assuming the reader is aware that this is a translation and the text is based in the source language's location/culture.
"It's raining cats and dogs" has an equivalent in most languages. "Lagom" in Swedish doesn't. You could say it's similar to the "itadakimasu" concept of 'being grateful'. It is often translated as 'enough', but even that is woefully lacking. "Itadakimasu" also falls under the sorry, no specific equivalent here banner since it is specific to JP culture.
What are you hoping to find from the individual words? The etymology of the word is described in the 'Itadakimasu History' section, with references to mountain tops, bowing, gratefulness. Are you looking for a single, one-size-fits all equivalent word? Are you looking to understand it's history, or how to use it? The article is pretty comprehensive. And let's bear in mind that we may be over-analysing. Thousands of Japanese 5 year olds probably said itadakimasu today without a thought.
It seems that production versions of these cutting edge techniques come out very soon after the paper is released (in this case just a few months). I wonder how long the internal development process for these big ML efforts are.
I'm not sure this is all that soon. The first paper using RNNs in an encoder-decoder framework from Hinton et al which blew the top off of phrase-based systems' BLEU scores was back in... 2013? It's been a long time.
And it's been an especially frustrating wait because whenever you mention how deep systems have made huge process on translation, someone will be sure to note that Google Translate produces total gibberish for Japanese-English and in general is pretty bad, and then you had to explain that as far as anyone knows, Google may be publishing papers on how RNNs translate great but that doesn't mean they've rolled them out to the public Google Translate yet, which looks like making excuses. Now we get to see a productized version of the RNNs out in the wild.
The french translation is pretty bad. The funny thing to try is to double translate english => french => english and compare both texts. If the results are way off, you know the translation is incorrect.
I'm excited to see if these changes trickle down to the Latin model, which has seen improvement over the years but at a pace slower than non-dead/historical languages.
Even though I appreciate the quality of the new translation, on the translation example on the image with the 2 phones, I find the old translation more insightful (even if not grammatically correct) than the new one.
I.e. I prefer: "No problem can be solved from the same consciousness that they have arisen" to "Problems can never be solved with the same way of thinking that caused them"
I agree, this seemed like a poor choice for demonstrating the improvements in translation. I would personally translated it as "No problem can be solved via the same manner of thinking as caused them".
Because we (not we as in the people but ICANN or whoever's in charge) are allowing corporations to use trademarks as top level domains. While before the top level domains belonged to countries or were general, now they can also be populated by those rich enough. Personally I see it as brands encroaching on a previously "public" space. Would Google allow me to register fuck.google or anything that could damage their brand? I highly doubt it. I wouldn't find it so bad if any joe schmo could create their own TLD, but this is an instance of allocating address space to the most powerful and letting control it as free advertising. It's not a technical problem by any means, but I see it as a moral one.
Well fuckMicrosoft.com was a thing [0], unless with the .google.com thing you meant as some kind of subdomain on Google's site. I don't think those are available for registration anyway. Also, FWIW, a .sucks TLD exists. [1]
Simple: I just don't see the point on using these new TLDs, they are confusing, it's not clear how the work and stupidly expensive... Seems just as an snobby thing.
{kind=link}
{kind=link}
{kind=link}