The profusion of Category-theoric abstractions and some of the more recent purely functional norms in Haskell are like the PhD-level version of `AbstractVisitorContextFactoryBuilder` which, aside from all the unnecessary cognitive load, lead to enormous dependency graphs of the npm variety.
Personally, I wonder if uniqueness types in languages like the sadly forgotten Clean (a close relative of Haskell) would have been better than the whole Monad/Arrow thing. All of that abstract theoretical stuff is certainly fascinating but it's never seemed worth all the bother to me.
On the other hand, in SML you get all the benefits of strong HM type inference/checking, immutability by default, etc, etc.. while also still being able to just `print` something or modify arrays in place. SML's type system isn't higher-order like Haskell's so its solution to the same problem Haskell solves with type classes isn't quite as elegant but otherwise SML is the C to Haskell's C++.
I find there are two main problems with monads in Haskell:
- Monad is just an interface (with nice do-notation, to be sure), but it's elevated to an almost mythic status. This (a) causes Monad to be used in places which would be better without (e.g. we could be more generic, like using Applicative; or more concrete by sticking to IO or Maybe, etc.) and (b) puts off new comers to the language, thinking they need to learn category theory or whatever. For this reason, I try to avoid phrases like "the IO monad" or "the Maybe monad" unless I'm specifically talking about their monadic join operation (just like I wouldn't talk about "the List monad" when discussing, say, string splitting)
- They don't compose. Monad on its own is a nice little abstraction, but it forces a tradeoff between narrowing down the scope of effects (e.g. with specific types like 'Stdin a', 'Stdout a', 'InEnv a', 'GenRec a', 'WithClock a', 'Random a', etc.) and avoiding the complexity of plugging all of those together. The listed advantages of SML are essentially one end of this spectrum: avoiding the complexity by ignoring the scope of effects; similar to sticking with the 'IO a' type in Haskell (although even there, it's nice that Haskell lets us distinguish between pure functions and effectful actions).
Haskell has some standard solutions to composing narrowly-scoped effects, like mtl, but I find them to be a complicated workaround to a self-imposed problem, rather than anything elegant. I still hold out some hope that algebraic effect systems can avoid this tradeoff, but retro-fitting them into a language can bring back the complexity they're supposed to avoid (e.g. I've really enjoyed using Haskell's polysemy library, but it requires a bunch of boilerplate, restrictions on variable names and TemplateHaskell shenanigans to work nicely).
Well said. This is exactly my gripe with Haskell monads. There are too many places where the hierarchy isn't uniform and there are a bunch of special monads like IO and List. It leads to the same ambiguous "is a" problem of complicated OO hierarchies and is one of the reasons they don't compose well.
The ironic thing is that these algabraic effect systems have a feel/control flow pattern that's quite similar to exception handling from the OO languages or interrupt handlers in low-level code.
It's much easier to just say "this piece of code is impure, it may do X, Y, and Z and if so then ..." than to try and shove everything ad-hoc into the abstract math tree. But then you lose the purity of your language and it's really awkward in a language whose primary concern is purity. That may be a reason why algebraic effects seem a bit more natural in OCaml.
I don't think there's a way to not use monads, because a ton of everyday things just work in a monadic way, things like lists, or statement sequences in presence of exceptions. I think it's wiser to admit and use these properties instead of ignoring them.
Ignoring maths that underlie computation when writing software is like ignoring math that underlies mechanics when building houses: for some time you can get by, but bigger houses will tend to constantly fall or stand a bit askew, and the first woodpecker to fly by would ruin the civilization, just as the saying goes.
Uniqueness types were a nice idea indeed. I suspect linear types (or their derivative in Rust) do a very similar thing: data are shared XOR mutable.
I recently read a blog post by someone who worked as a carpenter for a summer. He said he disliked the saying “measure twice, cut once” because actual carpenters avoid measuring as much as possible! For example, to make a staircase, you could try using simple trig to calculate the lengths of the board, angle of stair cut outs, step widths, etc. But that would all be wasted effort because you can’t actually measure and cut wood to sufficient precision. Instead, you need to just get rough measurements and then use various “cheats” so the measurements don’t matter, like using a jig to cut the parallel boards at exactly the same length (whatever it turns out to be).
Analogy to monads is this: yes, there are mathematical formalisms that can describe complex systems. Everything can be described by math! That’s literally its one job. But will the formalisms actually help you when the job you’re doing has insufficient achievable precision (eg finding market fit for a website)?
I think that the metaphor leaks badly. Finding market fit is like deciding on the general shape of the staircase. Execution of whatever design still needs the stairway to be strong and reliable all the same.
Writing code is a much more precise activity that cutting wood. Using "cheats" can get you somewhere, but due to the precise nature of the machine logic, the contraption is guaranteed to bend and break where it does not precisely fit, and shaving off the offending 1/8" is usually not easy, even if possible.
> But will the formalisms actually help you when the job you’re doing has insufficient achievable precision (eg finding market fit for a website)?
In my experience, this is exactly the problem Haskell's core abstractions—monads among them—help with!
What do you need when you're trying to find product-market fit? Fast iteration. What do Haskell's type system and effect tracking (ie monads) help with? Making changes to your code quickly and with confidence.
1. Make clean, well-factored code the path of least resistance.
2. Provide high-level, reusable libraries that keep your code expressive and easy to read at a glance despite the static types and effect tracking.
3. Give you guardrails to change your code in systematic ways that you know will not break the logic in a wide range of ways.
If I had a problem where I'd need to go through dozens of iterations before finding a good solution—and if libraries were not a consideration—I would choose Haskell over, say, Python any day. And I say this as someone who writes a lot of Python professionally these days. (Curse library availability!)
Honestly, Haskell has a reputation of providing really complicated tools that make your code really safe—and I think that's totally backwards. Haskell isn't safe in the sense that you would want for, say, aeronautical applications; Haskell programs can go wrong in a lot of ways that you can't prevent without extensive testing or formal verification and, in practice, Haskell isn't substantially easier to formally verify than other languages. And, on the flipside, Haskell's abstractions really aren't complicated, they're just different (and abstract). Monads aren't interesting because they do a lot; they're interesting because they only do a pretty small amount in a way that captures repeating patterns across a really wide range of types that we work with all the time (from promises to lists to nullable values).
Instead, what Haskell does is provide simple tools that do a "pretty good" job of catching common errors, the kind of bugs that waste a lot of testing and debugging time in run-of-the-mill Python codebases. This makes iteration faster rather than slower because you get feedback on whole classes of bugs immediately from your code, without needing to catch the bug in your tests or spot the bug in production.
As a bit of an aside, it's interesting that the CS (Haskell, mainly) descriptions of a Monad are much more complicated than the math.
Knowing a little bit of maths, but not much category theory, the wiki entry for Monads(Category Theory) is pretty clear. First sentence: A Monad is an endofunctor (a functor mapping a category to itself), together with two natural transformations required to fulfill certain coherence conditions. Easy.
Knowing a bit of programming, but not much Haskell, reading the entry for Monad (functional programming) or any blog post titled "A Monad is like a ...", it almost seems as if the author is more confused about what a Monad is than me. The first sentences of the Wikipedia article for example are a word-salad. With dressing.
From an outsider's perspective, it's almost as if a monad in functional programming is not a 1:1 translation of the straightforward definition of category theory, leading to an overall sense of confusion.
The formal definitions are straightforward enough, but the definitions alone don't really motivate themselves. A lot of mathematical maturity is about recognizing that a good definition gives a lot more than is immediately apparent. Someone without that experience will want to fully understand the definition, and fairly so -- but a plain reading defies that understanding. That is objectively frustrating.
> As a bit of an aside, it's interesting that the CS (Haskell, mainly) descriptions of a Monad are much more complicated than the math.
I actually do agree with this, though. I feel like monads are much simpler when presented via "join" (aka "flatten") rather than "bind"; and likewise with applicative functors via monoidal product (which I call "par") rather than "ap". "bind" and "ap" are really compounds of "join" and "par" with the underlying functorial "map". That makes them syntactically convenient, but pedagogically they're a bit of a nightmare. It's a lot easier to think about a structural change than applying some arbitrary computation.
Let's assume the reader knows abut "map". Examples abound; it's really not hard to find a huge number of functors in the wild, even in imperative programs. In short, "map" lets us take one value to another, within some context.
Applicative functors let us take two values, `f a` and `f b`, and produce a single `f (a, b)`. In other words, if we have two values in separate contexts (of the same kind), we can merge them together if the context is applicative.
Monads let us take a value `f (f a)` and produce an `f a`. In other words, if we have a value in a context in a context, we can merge the two contexts together.
Applicative "ap", `f (a -> b) -> f a -> f b`, is "par" followed by "map". We merge `(f (a -> b), f a)` to get `f (a -> b, a)`, then map over the pair and apply the function to its argument.
Monadic "bind", `(a -> f b) -> f a -> f b`, is "map" followed by "flatten". We map the given function over `f a` to get an `f (f b)`, then flatten to get our final `f b`.
It's a lot easier to think about these things when you don't have a higher-order function argument being thrown around.
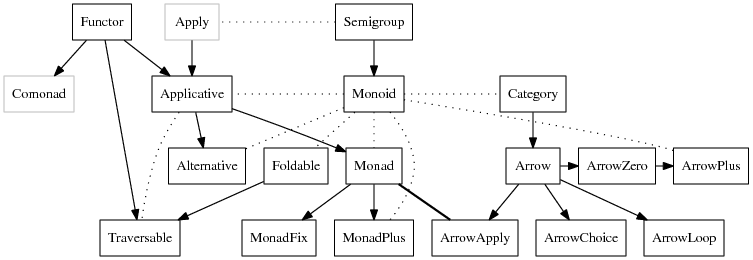
The problem isn't with the mathematical concept of monads, it's that Monad is a typeclass in a hierarchy along with other totally abstract category theoric classes introduced at different stages and people use them with varying levels of knowledge and ignorance so things are placed arbitrarily and there are a bunch of ambiguities. Just look at this [0] mess. Is that really what we want?
It's used pervasively in low-level code because the idealism of monads just doesn't cut it. In my opinion, this proves that the pragmatism of side effects is a necessary evil for actually getting things done in a performant way.
Lazy evaluation has the same kind of issues. Most humans don't think that way, so performance suffers. This may be a universal problem as in my experience, Haskell doesn't have good tooling to help with this issue.
Always immutable is another large issue. Yes, there's a ton of safety in immutability and it's the right tool for MOST code. Compilers aren't prefect and there seem to be an endless stream of situations where the compiler can't figure out if it is safe to mutate "immutable" data to gain performance. For the foreseeable future, the ability to mutate can have huge performance dividends.
Finally, Haskell and it's libraries are prone to rather academic programming styles and techniques. These are amazing and beautiful. They also can be hard to grep even if you know the math. When you consider that the overwhelming majority of programmers don't know the math, it seems plain that these constructs are a detriment to pragmatic, non-academic usage.
> It's used pervasively in low-level code because the idealism of monads just doesn't cut it. In my opinion, this proves that the pragmatism of side effects is a necessary evil for actually getting things done in a performant way.
It seems like you aren't very familiar with the ways Haskell programmers deal with side effects and mutation. UnsafePerformIo is sometimes needed, and there are a few common idiomatic ways to use it, but there are usually better options. What at first looks like an impenetrable wall between the IO monad and pure code is actually surprisingly permeable, just not (usually) in ways that violate expected semantics. For instance, you can read a file into a string in the IO monad and pass the string into pure code to process it. The string is lazy, so the pure code actually triggers the file to be read as it's consumed.
Another escape hatch is the ST Monad. It allows you to run imperative computations (i.e. use mutable variables and arrays) within pure code. Since the ST computations are deterministic, they don't violate any important guarantees about pure code. You can't read and write files from the ST Monad, but if you want to do array-based quicksort or something similar it's available.
Some aspects of Haskell are hard to work with. You're right that laziness introduced some performance issues that can be tedious to fix, and some of the libraries are hard to use. However, it's a perfectly reasonable tool for many general-purpose programming applications. It's not a replacement for C, but you could say the same thing about C# or Java or any other language with a garbage collector.
Wait, I thought that lazy io (e.g. getting a lazy string back from "reading" a file, which triggers subsequent reads when you access it) was widely considered bad and a mistake.
This depends very much on the context. Using something like `readFile` without carefully exhausting it is absolutely a mistake in a long lived application or a high volume web server, and in a setting like that reaching for that kind of an interface and hoping future modifications preserve the "reads to exhaustion in reasonable time" is questionable at best.
On the other hand, in a program that handles a small number of files and doesn't live long after file access anyway (say a small script to do grab a couple things, crunch a few numbers, and throw the result at pandoc), there's nothing wrong with lazy IO and it can be quite convenient.
Lazy IO is really useful for commands which stream data over stdio, e.g. this is a really useful template, where 'go' is a pure function for producing a stdout string from a stdin string:
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString.Lazy.Char8 as BS
main = BS.interact go
go :: BS.ByteString -> BS.ByteString
go input = -- Generate output here
If you don't mind Haskell's default String implementation, then it's just:
main = interact go
go :: String -> String
go input = -- Generate output here
Yes, that's true. I thought about mentioning that in my comment, but it seemed like a bit of a digression and it was already getting a bit wordy.
Anyways, the problem is that you might open a file, read it into a string, close the file, and then pass the string into some pure function. The problem is that the file was closed before it was lazily read, and so the string contents don't get populated correctly; you get the empty string instead, or whatever was lazily read before the file was closed.
That was a design oversight from the early days. If you know about it, it's pretty easy to work around it in simple applications. There are some more modern libraries for doing file IO in a safer way, but I haven't used them and don't really know what the details are.
Reasoning about haskell performance is hard because it is a lazy language and the compiler pulls a lot of tricks. In SML, code is executed in some sense roughly in the order it is written whereas in haskell it is very hard to know when something will be executed.
{kind=link}
Can you elaborate on what those flaws are?